Чистый Лист
-
Постов
323 -
Зарегистрирован
-
Посещение
-
Победитель дней
9
Посетители профиля
1 165 просмотров профиля





Достижения Чистый Лист
")





-
 У меня чистый пдф, не скан - гораздо проще. Я его импортирую и у меня текст - отдельно, картинки - отдельно. соответственно текст в кривых, его в систему распознавания и в Гугл AI. Потом просто меняю текстовые блоки на переведенные. Со сканами сложнее - PDF загоняем в OCR (программа распознавания текста). Она сама вырезает картинки, распознает текстовые блоки, потом экспорт в PDF, импорт в программу вёрстки и работа со всем этим постранично. Качество будет хуже, OCR не всегда правильно конвертит текст/таблицы, режет рисунки криво. Поэтому если красиво, то долго, может даже отдельно вырезать из джипегов картинки и верстать с нуля поверх оригинальных страниц (в принципе, страницы стилизованы все одинаково), ничего особо сложного, только картинки ручками вырезать/сохранять/импортировать. Как-то так. К примеру мой сервис-мануал 209 страниц, 120 переведено - по времени 3 месяца в свободное время на работе (час-два в день). Чисто на энтузиазме. К весне закончу.
У меня чистый пдф, не скан - гораздо проще. Я его импортирую и у меня текст - отдельно, картинки - отдельно. соответственно текст в кривых, его в систему распознавания и в Гугл AI. Потом просто меняю текстовые блоки на переведенные. Со сканами сложнее - PDF загоняем в OCR (программа распознавания текста). Она сама вырезает картинки, распознает текстовые блоки, потом экспорт в PDF, импорт в программу вёрстки и работа со всем этим постранично. Качество будет хуже, OCR не всегда правильно конвертит текст/таблицы, режет рисунки криво. Поэтому если красиво, то долго, может даже отдельно вырезать из джипегов картинки и верстать с нуля поверх оригинальных страниц (в принципе, страницы стилизованы все одинаково), ничего особо сложного, только картинки ручками вырезать/сохранять/импортировать. Как-то так. К примеру мой сервис-мануал 209 страниц, 120 переведено - по времени 3 месяца в свободное время на работе (час-два в день). Чисто на энтузиазме. К весне закончу. -
Ладно, я понял )
-
Как правило, так и есть в роликах. основные термины типа корзины, вала знают, а остальное для них - "пластина с болтами". Я перевод всё равно не брошу, хотя бы чисто для себя, если другим не надо. Это называется дофига свободного времени на работе. Тем более я по профессии - графический дизайнер, верстальщик, мне переверстать мануал как два пальца об асфальт.
-
Ну и самому интересно устройство мотоцикла, интересно почитать в переводе. Мне на нем катать и обслуживать, весьма полезная книжка.
-
Доброе дело людям сделать. Мануала на русском нет, теперь будет. Я ИИ для перевода использую, но местами он прям чудит по терминам. Пересмотрел и ролики и схемы - все по разному и непонятно. Я бы не спрашивал помощи, если бы не нуждался. Та же схема сцепления - вообще в инете в разнобой по терминам. Ну какбэ нет так нет. Потом поправят люди, исправлю по факту.
-
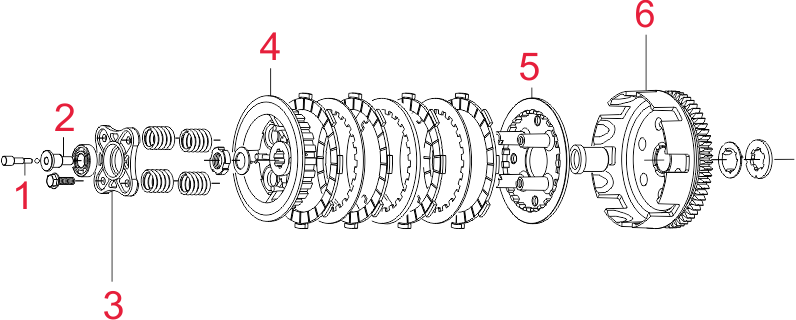
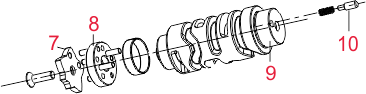
Добрый день! Перевожу сервис-мануал, нужна помощь в определении названий деталей: Сцепление: КПП:

-
Всё, зима пришла. Снег выпал, по прогнозу стабильный минус. Ни рыбалки, ни покатушек. Только нескончаемый ремонт в квартире на полгода.
-
Почему упоминание харда вызывает у вас лютое веселье. Почитал его посты, много думал. Пришёл к пониманию.
-
Рукастый, таких мы уважаем.
-
Ненене - ховера! Путь Харда.
-
Не. Эта дорожка для меня закрыта. Ко второму мотоциклу прицепом идёт гараж. А они у нас стоят как пять ТВСов или три баджобоксера. Вот раньше нафиг не нужен был этот гараж, а тут, поковырявшись с мотоциклом, захотел. Но не вывезу.
-
Спасибо, у меня ещё этот не кончился.
-
Самый лучший мотоцикл - этот тот мотоцикл, который у тебя есть на данный момент.